

Text Coder X for SPSSとは?
「Text Coder X for SPSS」はIBM SPSS Statisticsを利用しながら、メニュー操作だけで稼働する日本語分析用のアドオンモジュールです。テキストデータの変数と回答者ID、併せて分析したい変数を選択するだけで稼働します。
テキストデータのパワーを分析に加える
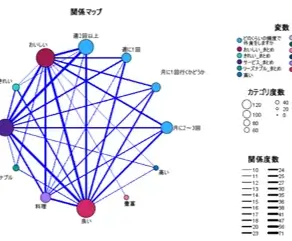
関連キーワードをグラフで確認
抽出したキーワードを「関連マップ」で確認することで、キーワード同士の関係性を把握することが可能です。
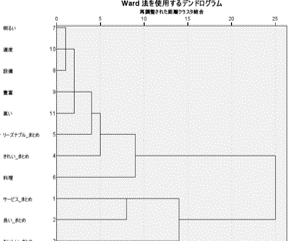
階層クラスタで類似単語を分類
デンドログラムを利用してキーワードの階層クラスタリングを把握することが可能です。
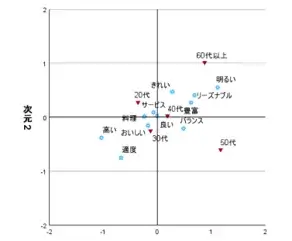
コレスポンデンス分析
コレスポンデンス分析(別途:要Categoriesオプション)によりキーワードとカテゴリデータを一緒に可視化することが可能です。
Text Coder X for SPSSの操作イメージ
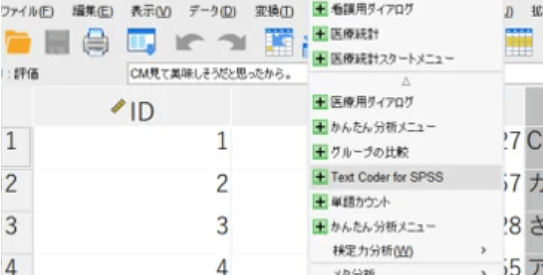
メニューから簡単操作
SPSS Statistics上のメニューから操作が可能。別ツールを起動することなく、テキストデータから品詞を抽出し、テキストデータを利用することができます。
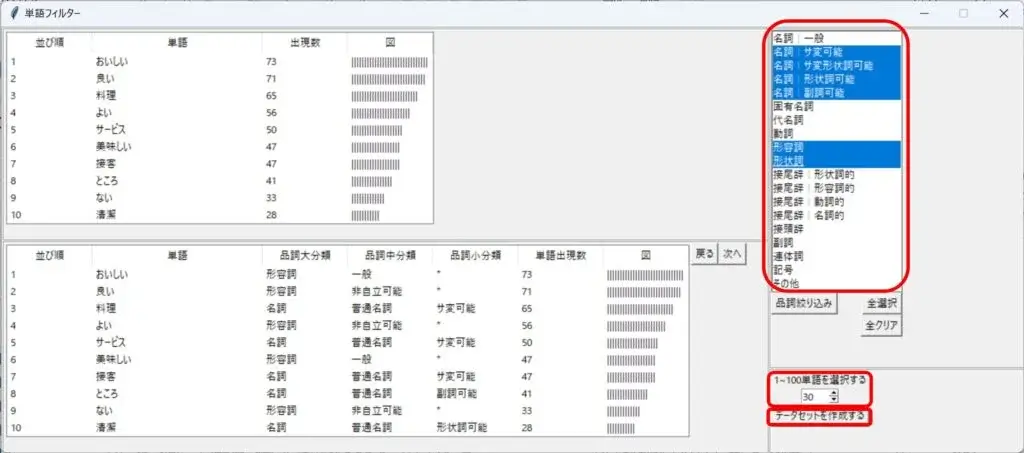
テキストデータを指定
日本語の文章から単語(キーワード)を抽出。抽出する単語を選択した品詞で絞り込み抽出する単語を出現頻度の高い順に表示します。
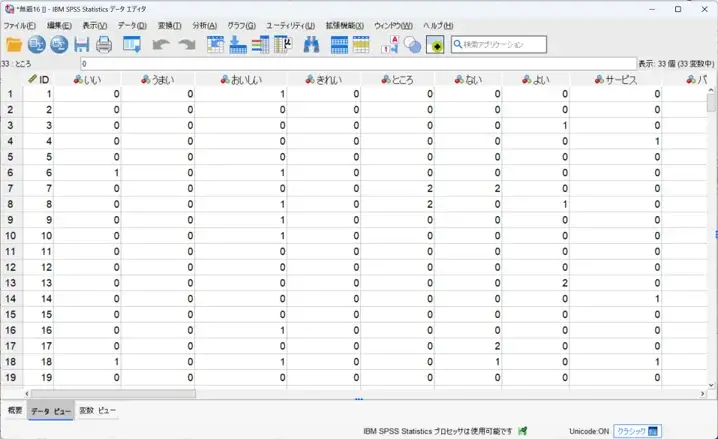
コード化データを作成
コード化したSPSSファイルをすぐさま作成。回答者ごとに単語の使用頻度をカウントしたデータを生成。回答者ごとに単語を使用したかのフラグ(0/1)データを生成します。
Text Coder X for SPSS 稼働環境
必須ソフトウェア:IBM SPSS Statistics Base or Standard v29.x以上
IBM SPSS Statisticsの稼働環境に準拠
-Windows OS: SPSS Statisticsがサポートしている
-MacOS: SPSS StatisticsがサポートしているMacOS
※お持ちのSPSSがDVDパッケージ版でもダウンロード版でもすべてのSPSS v29以上にアドオン可能です。